
Business challenge
Solution architecture
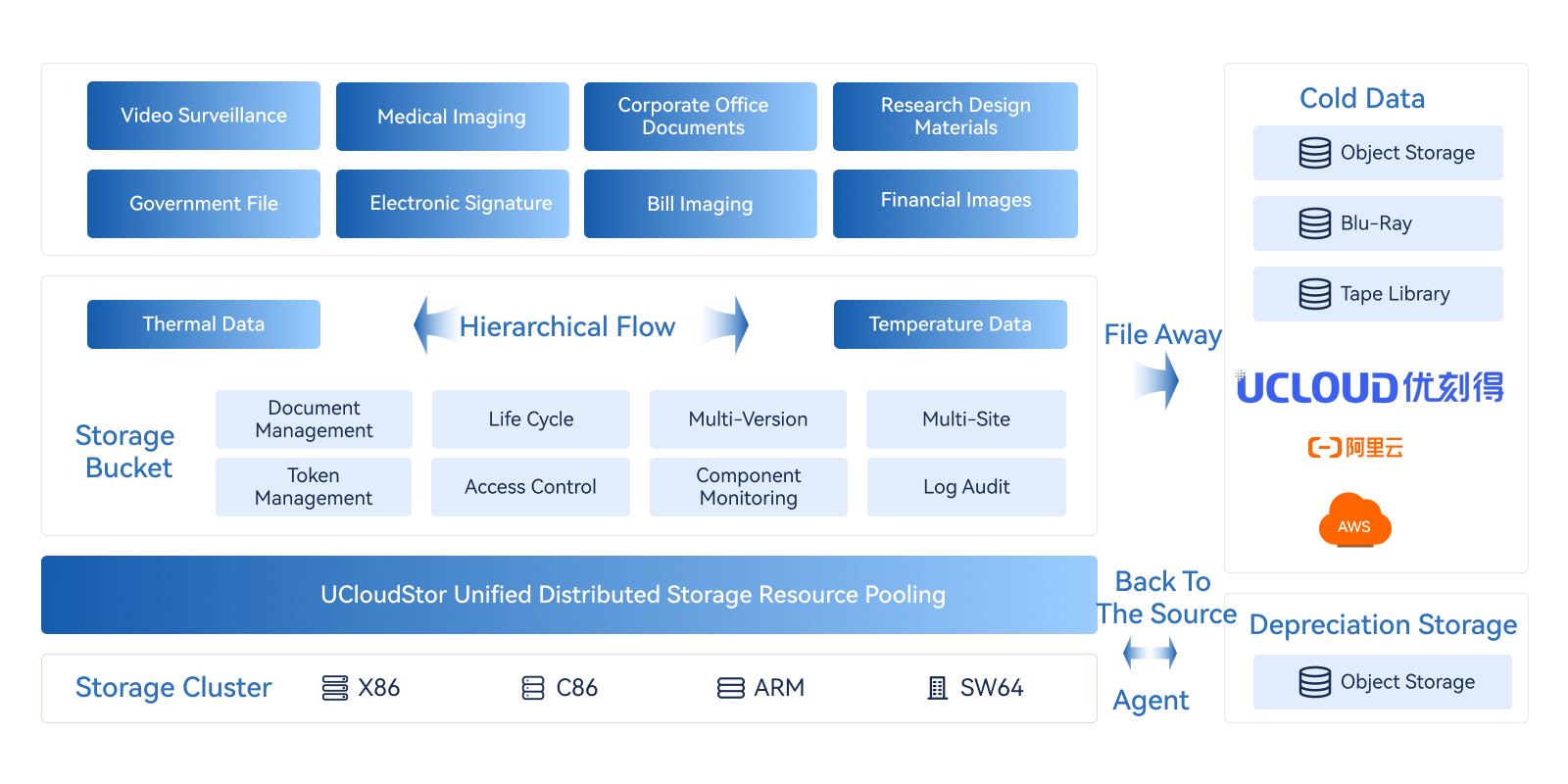
Scheme characteristics
Scheme value

Improve data availability
Fine-grained policies are used to control data in a specified range to synchronize data from multiple sites, improving data reliability. The multilevel fault domain mechanism ensures service data availability while meeting data compliance and security requirements
Both performance and cost
Storage clusters that use the full flash or cache solution meet high-performance read and write requirements, and combine low-cost large-capacity storage clusters with data lifecycle management capabilities to store and archive massive data at low cost
Automated data management
By defining life cycle rules, you can automatically migrate and archive data, change storage categories, and delete data based on data features and requirements to optimize storage resource utilization and data management efficiency
