
Product advantage
Product architecture
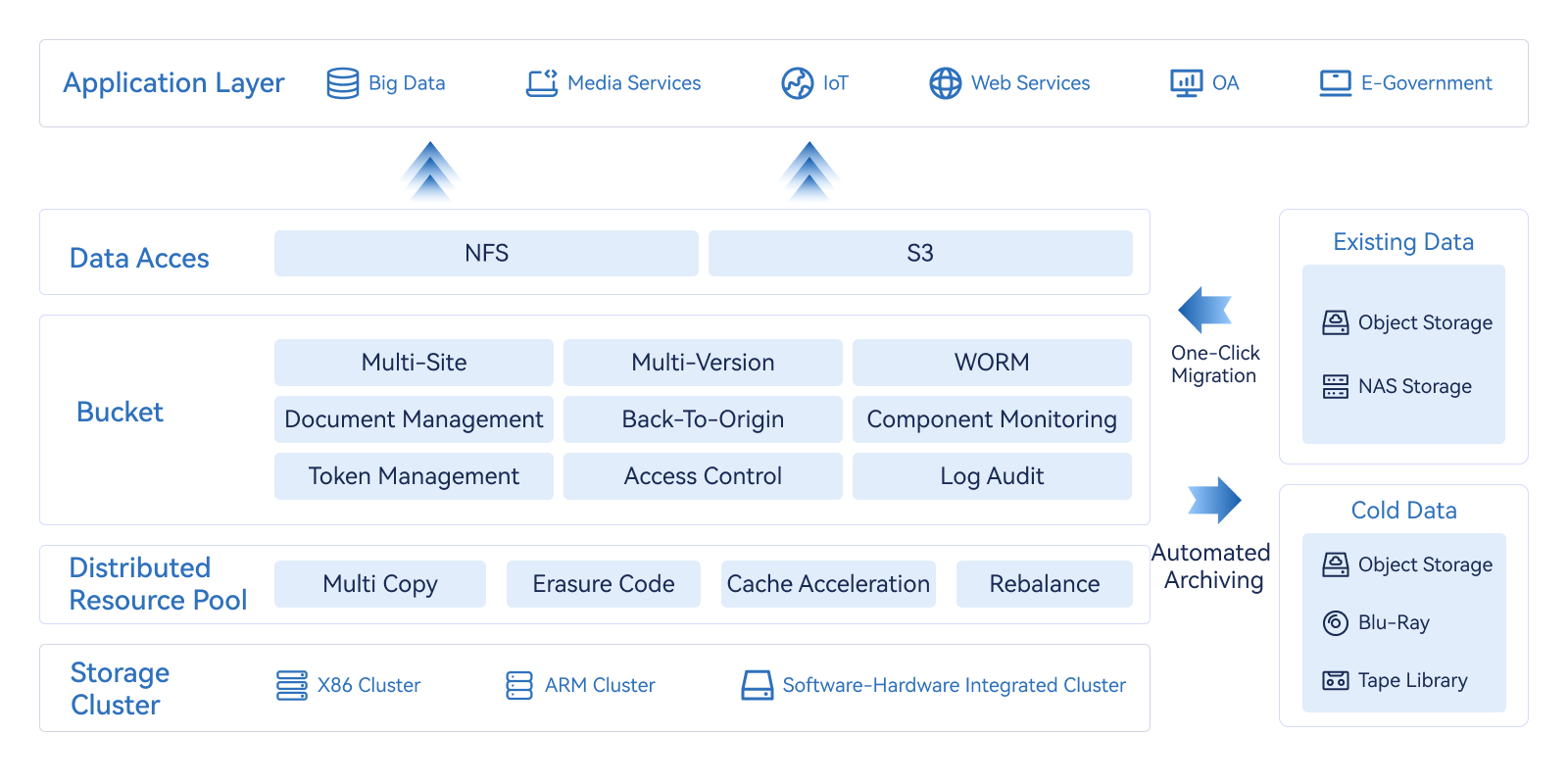
Product characteristics
Supports multi-copy and erasure code redundancy, and improves data availability and reliability with multilevel fault domain self-healing capabilities
The multi-version capability facilitates tracking and auditing of data changes. The WORM feature protects critical data against unauthorized tampering
Multi-site bidirectional data synchronization, to deal with data center level faults, and to achieve nearby data access, reduce access latency
Object-level data protection is achieved through server-side encryption, and users do not need to manage keys to improve data security
The log dump function automatically records object data access logs for security analysis, compliance audit, and resource tracing
Users and keys are managed, quotas are set, and access rights are controlled to achieve fine-grained permission control and improve data security
Cache acceleration solution, high-speed disk read and write distribution, hot and cold data automatic flow, optimize performance while reducing the overall cost
You can customize the N+M value of erasure codes based on scenarios to provide reliable data protection and effectively control and reduce the overall storage cost
Provides data lifecycle management. You can set lifecycle rules to automate data archiving in a specified range
When nodes are scaled online, cluster performance increases linearly with capacity expansion, taking full advantage of the read and write performance of each node
One-click import of existing files and object data, full automatic migration, visual progress data clearly show the migration process
The backsource agent function seamlessly leverages existing storage, unified data access and reduces initial storage costs
Manage multiple clusters in a unified manner, easily configure cross-cluster data flow, and better manage and allocate storage resources in a global view
It also supports client and console graphical file management to easily browse, find and manage files
Rich alarm rules and comprehensive multi-dimensional monitoring indicators help you learn about the running status of clusters and object storage devices
